As a product manager, I spend a lot of time poking around technology. Recently, I was experimenting with a particular algorithm and became curious about surname distribution in the United States. I wondered whether I could find lists of last names on the internet – you can find anything on the internet, right? My search led me to machine learning websites, government websites, benchmark datasets hosted across the web … and I was faced with a perennial question: how do I gauge whether and how to use “found data” on the internet? In an age where an ever-increasing amount of digital information is readily available, sourcing data is trivial – but assessing its quality is nearly impossible. There are no global standards and few best practices around data verification, quality assessment, and use case validation. It’s a digital free for all.
The health of a dataset has lasting impact because data lives on through its applications. When we think about the potential harms of AI, from sexist hiring algorithms to models that equate not having access to healthcare with not needing healthcare, we tend to focus on the output rather than the input. However, many of the issues we experience in AI come from the training data at the very beginning of the process. The encoded biases in the initial dataset will inevitably be captured in the algorithm, but by the time we realize this it might already be perpetuating those harms in the real world.
The Data Nutrition Project (DNP) aims to reduce these potential harms. Since launching the DNP in 2018 through the Assembly Fellowship at The Berkman Klein Center, I’ve worked alongside a team of researchers, data practitioners, and policy experts to create practical, standardized tools that mitigate problematic algorithmic systems by improving dataset quality.
Our journey began among buzzing university halls and many skipped meals. As the team thought through the challenges of found data, we snacked on whatever food was left around the space. This must have subtly shaped our thoughts, because our conversation turned towards the Food Nutrition label and the ways in which it had shaped our behaviors (and we were not alone). Our familiarity with the Label had also caused us, on occasion, to pause before eating something without the Label, meaning that it had changed our behavior even in the absence of the Label! This was especially interesting to us from the perspective of driving cultural change around dataset consumption. Would a dataset nutrition label work in a similar manner for data practitioners, both as a tool and also as an artifact that over time drives an expectation of transparency?
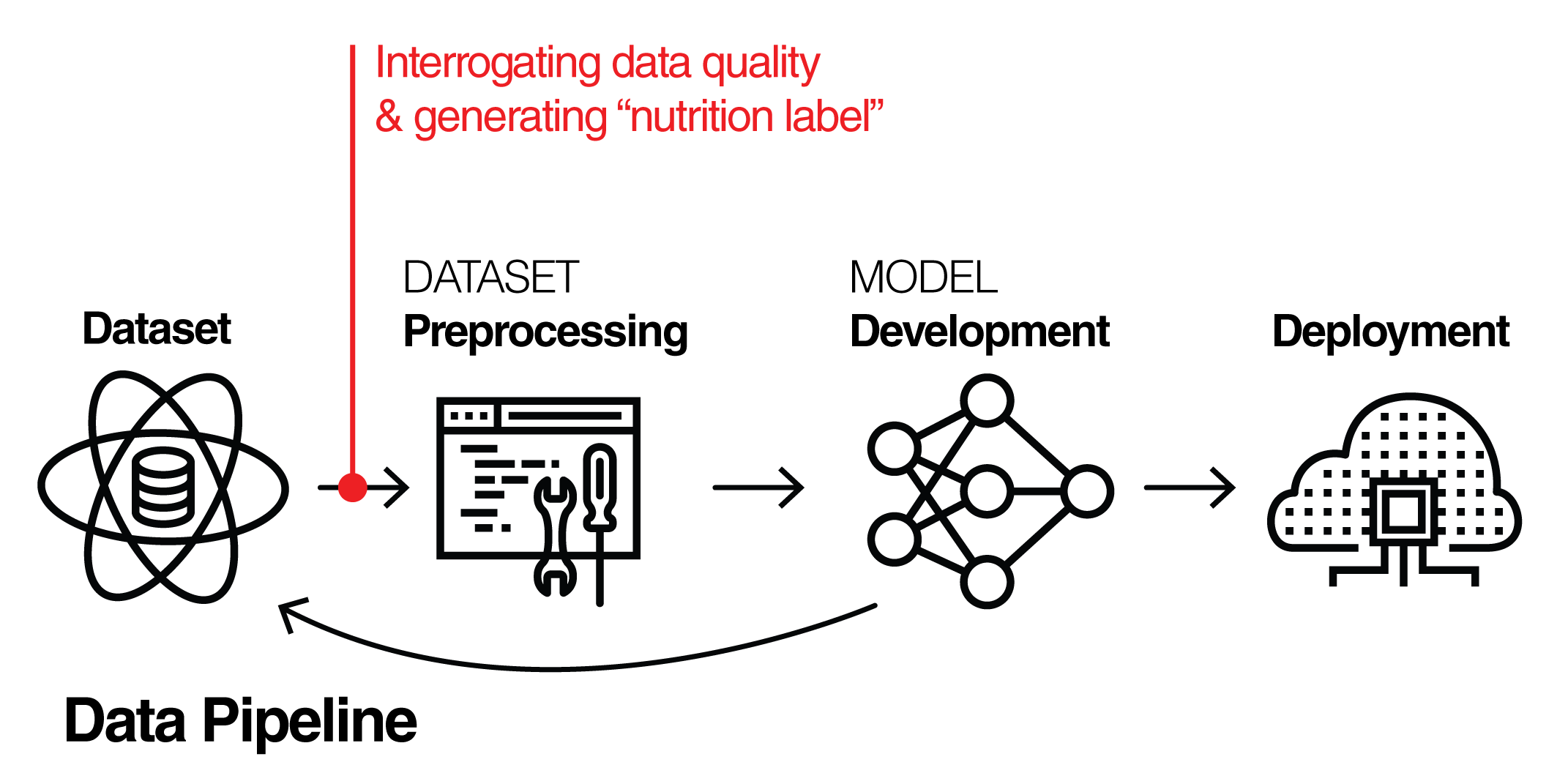 There is an opportunity to assess the quality of a dataset before it’s used to build a model
There is an opportunity to assess the quality of a dataset before it’s used to build a model
We started to kick around the question of what it would take to build a nutrition label for datasets that provide a standard, at-a-glance way of understanding the highlights (and lowlights) of the data. By the end of a rapid 4-month build, we had our first prototype Dataset Nutrition Label and a white paper published and on the web.
Three years later, the team has iterated through several versions of the Label though our goal remains the same: to provide meaningful information about how a dataset should or should not be used. The newest version of the Label, constructed while I have been a Consumer Reports Digital Lab Fellow, has been restructured to align more closely with intended use cases so that it is more useful for data scientists. This is akin to food warning labels that indicate which foods have gluten or allergens, rather than just list out the ingredients. Thus, critical information is both easy to understand and hard to miss.
For example, the Label for an open dataset about eviction data in New York City highlights potential real-world applications of the dataset, including predicting the amount of rent-stabilized units in the city, but also points out a known issue that some counts of existing units are estimations rather than exact values. The Label then further explains how to identify these estimates so that they can be intentionally removed if necessary. Data practitioners looking to use this dataset are thus able to quickly assess the intended use for the dataset, scroll through known issues, and learn applicable mitigation strategies.
 The Dataset Nutrition Label for the taxbills.nyc dataset
The Dataset Nutrition Label for the taxbills.nyc dataset
Similar to issues of fairness in society, there is no quick ‘solve’ to addressing bias in algorithmic systems. Rather, the goal is to highlight potential pitfalls and known mitigation strategies, and to do so in a standardized and legible way. During my time as a Consumer Reports Digital Lab Fellow, I’ve been focusing more directly on putting our prototype to work and seeing whether it functions well ‘in the wild’. We are also tackling new, complex challenges including quality controls on the Label itself and researching how to semi-automate the Label build process.
Although the pandemic has put a damper on our in-person snacking while we solve these problems, the team has adapted fairly well to zoom happy hours and expressing snack-adjacent thoughts through long strings of food emojis. If you, as well, like to think about dataset quality while snacking, please feel free to reach out and say hi! We’re just an email away.